About
Characteristics of a great projector
Over the course of the last two years I’ve written numerous articles on the good, the bad and the ugly of Event Sourcing as well as on our experiences building and maintaining a distributed enterprise-class based on this increasingly popular architecture style. One particular post ended up being a kind of retrospective on how we used to build projections and what we’ve learned from that. The gist of it is that I believe projectors (or denormalizers if you wish) must have all the autonomy to decide on how it does its work and when. So whether or not a particular projector runs in memory, uses a document database or can benefit from a traditional OR/M is a decision that should only concern that particular projector. As a consequence, it becomes pretty evident that each projector should be able to run at its own pace and restart itself when the need arises.
Principles of successful libraries
Another aspect of our profession that kept me busy last year is the notion of building libraries in a way that prevents you from ending up in a dependency hell. This was triggered by a book I read on the Principles of Package Design and which has fundamentally changed the way I look at software design. Inheritance for instance, is something I try to avoid, unless there’s a real functional relationship between the parent and its inheritors. A lot of libraries tend to ease the adoption by introducing base-classes that should get you going pretty fast. However, quite often these tend to hide too much magic and force you in a certain direction. And if you need something that the library wasn’t designed for, you’re either stuck or you have to fork the library and create your own version. With that said, let me introduce Liquid Projections for .NET.
Introducing Liquid Projections
Liquid Projections (or LP for short) is a set of highly efficient building blocks that each provide value on their own, but shine when used together to build synchronous and asynchronous projectors. It’s the culmination of years of (painful) experiences and has been battle-tested in production for almost two years now. It’s distributed as a collection of NuGet packages that ensure you only need to take dependencies on things you really need.
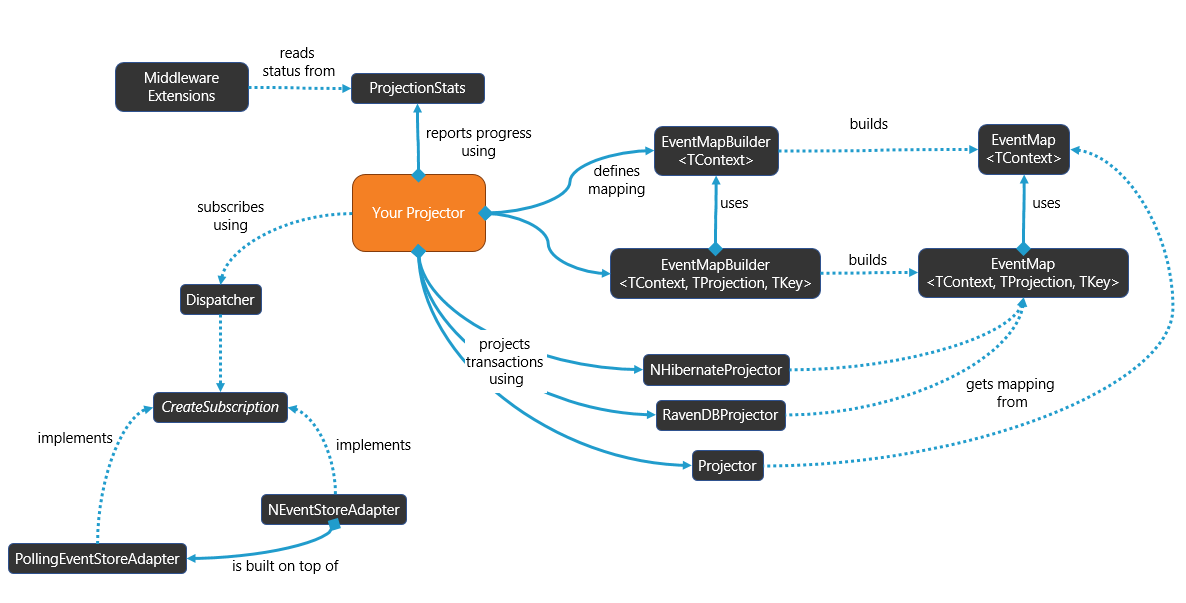
With the infinite knowledge of former colleague Ihar Bury (now Google), it fully embraces the async programming model and has been designed to run on as many .NET platforms as possible. As with all my open-source projects, it uses Semantic Versioning as well as Semantic Release Notes. We’ve been going through several breaking changes and many bug fixes, so we’ve finally reached calmer waters. Apart from some occasional talk on monoliths, Event Sourcing and micro-services, this is also the reason why I haven’t been actively talking about this library yet. You may wonder where the name is coming from. But if you know my other open-source projects, Fluent Assertions and Fluid Caching, you may see the resemblance….